Security issues in vibe-coded web applications: 20,000 apps built and analyzed
Vibe coding allows anyone to produce a working application simply by prompting an LLM. The big question is: how secure are those AI-generated apps? An analysis of over 20,000 vibe-coded apps shows that while overall security is improving compared to the early days of AI code, several types of weaknesses are very common.

More and more developers as well as non-developers are using large language models (LLMs) to generate code for web applications. I wanted to see how secure these applications are, so I generated a large number of web apps using different LLMs and then investigated their security using manual and automated analysis.
NOTE: For this analysis, “vibe-coded apps” refers to apps generated entirely by LLMs from prompts describing the vibe or theme of an application. I did not modify the generated code in any way.
Download a PDF version of this article
Generating 20k vibe-coded apps
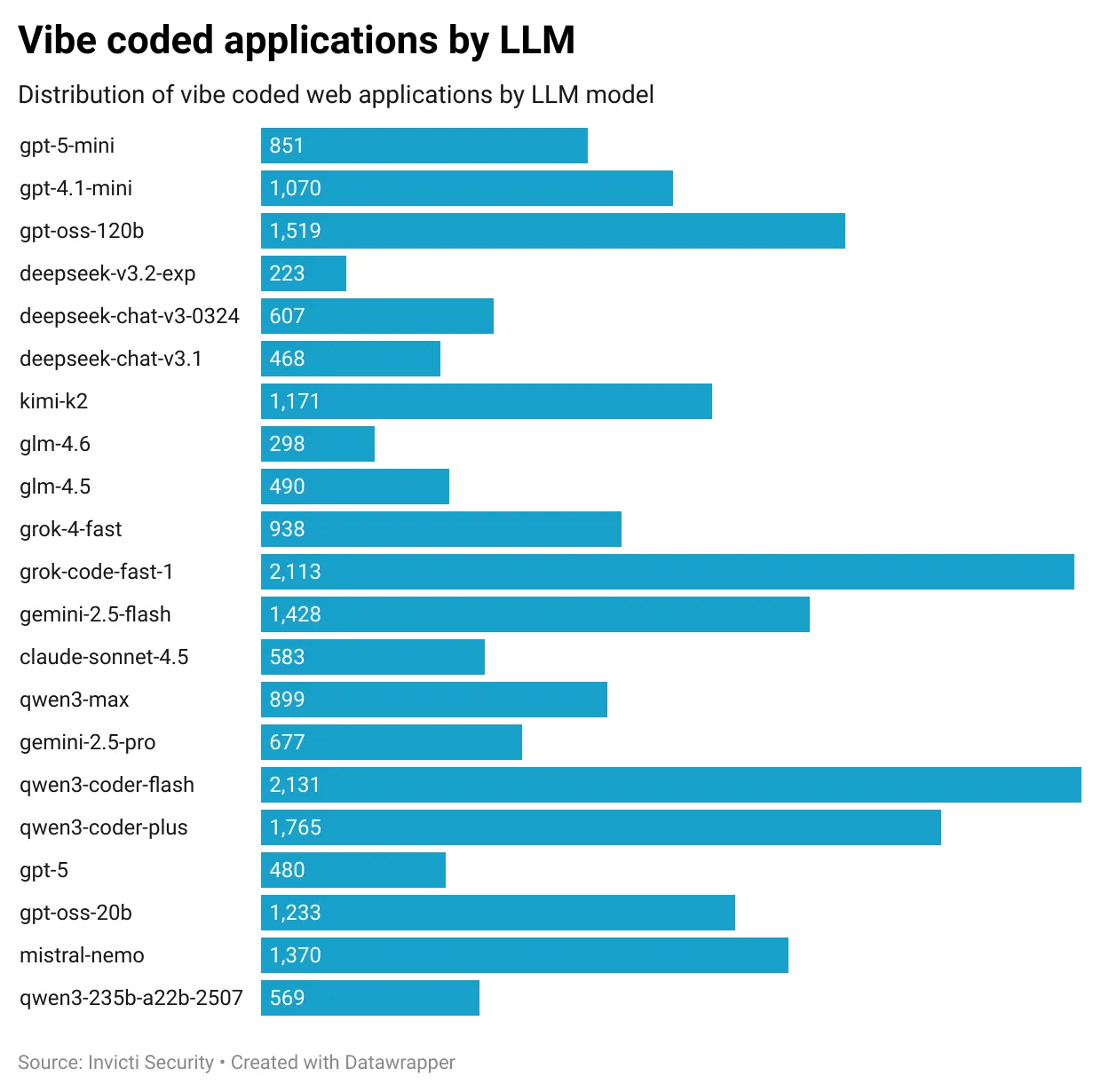
First, I generated around 20,000 web applications using different LLM models, such as gpt-5, claude-sonnet-4.5, gemini-2.5-pro, deepseek-chat-v3-0324, qwen3-max, and others. I also used some smaller models like gpt-5-mini, gpt-oss-120b, gemini-2.5-flash.
To generate the web apps, I used the OpenRouter API, which allows easy access to multiple LLMs through a single API. To make sure the apps are diverse enough, I used a wide range of prompts to introduce variety into the application set:
- The apps use many different themes, frameworks, technologies, requirements, and languages.
- I varied the temperature and other parameters to get different outputs from the LLMs.
- For architectural variety, some apps are only REST/GraphQL APIs, some are full-stack apps with frontends and backends, some are monoliths, and some are microservices-based.
- Most of the apps are containerized using Docker and Docker Compose.
In my prompts, I asked the LLMs to generate a production-ready web application with various requirements, themes, frameworks, and technologies. Each LLM task returned a list of files in a specific format. I then parsed this output and created the required files.
In the end, I was able to generate 20,656 web applications. You can see the distribution of the apps generated by each LLM model below:
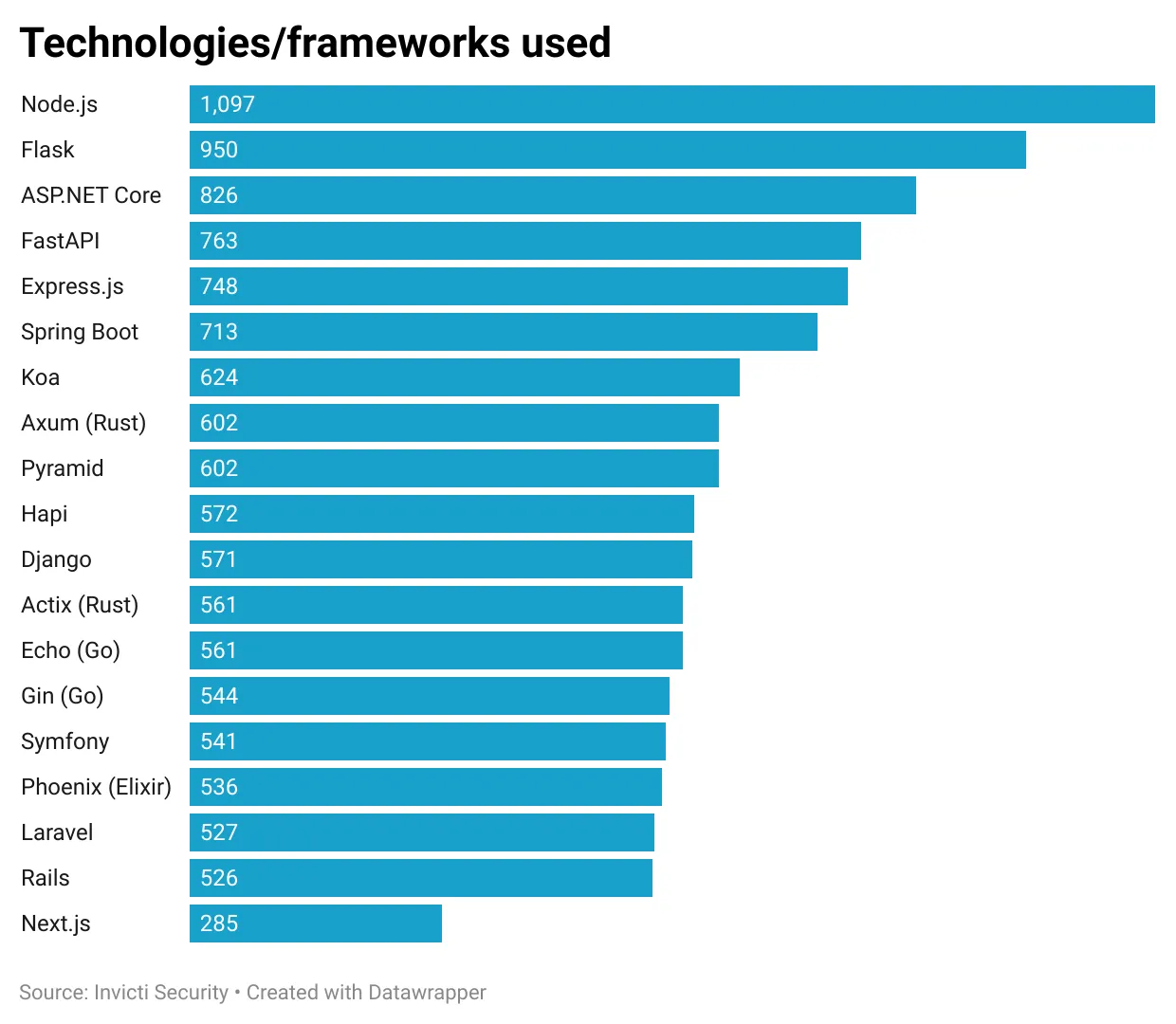
Technologies used in the apps
The web apps generated by the LLMs use a wide range of technologies and frameworks. I’ve extracted the technologies used, and the most common technologies in the test set are:
Examples of vibe-coded apps
To give you an idea of what I’ve been working with, here are two examples of the kinds of web apps generated by the LLMs. Each description comes from the LLM itself, and the screenshot shows the app as built.
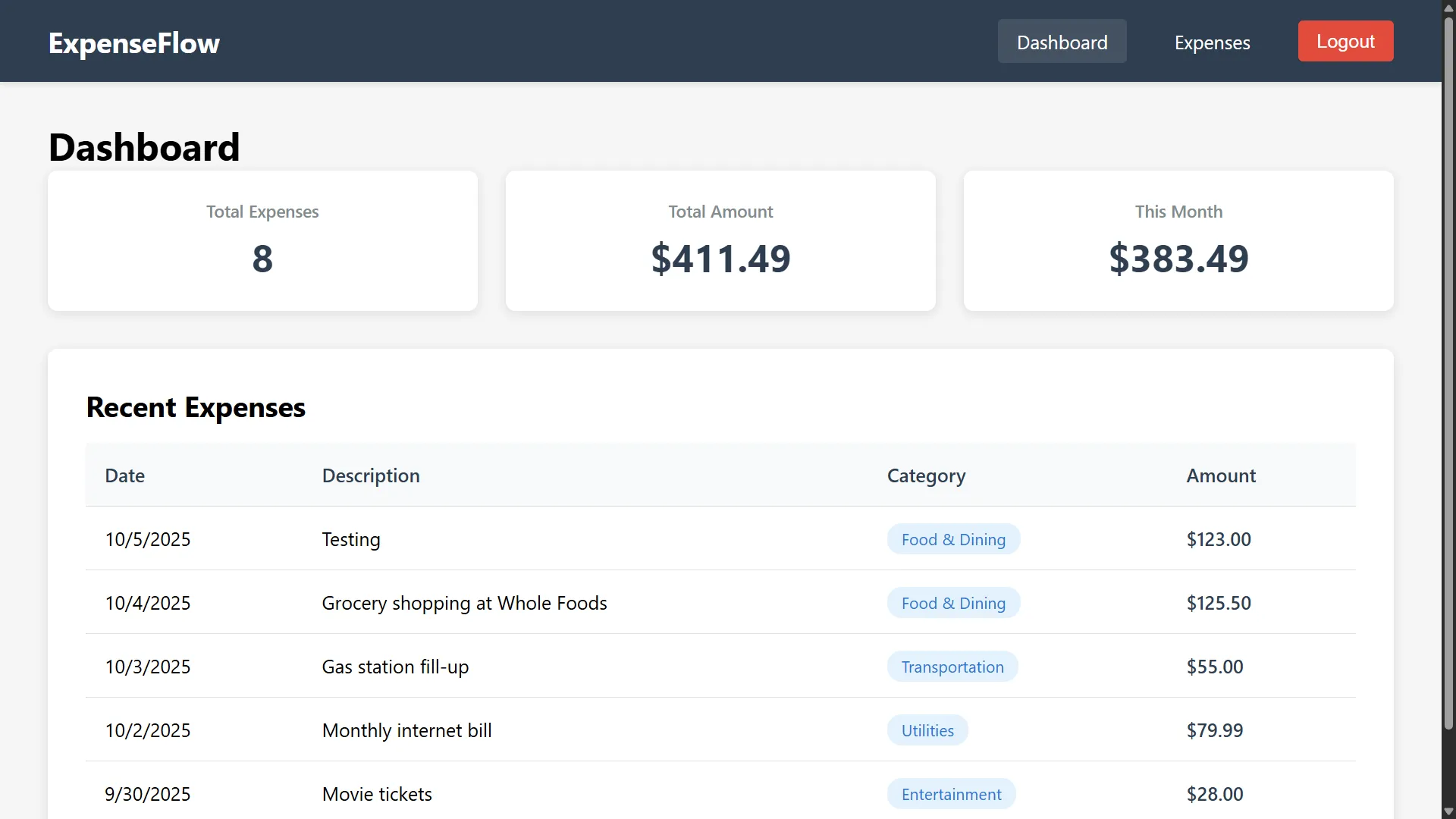
ExpenseFlow: An expense tracker created using claude-sonnet-4.5-604
ExpenseFlow
A full-featured expense tracking application built with Spring Boot, MySQL, and Vue.js. Includes user authentication, administrative dashboard, advanced search/filtering/paging capabilities, Swagger API documentation, and Nginx reverse proxy. Production-ready containerized deployment.
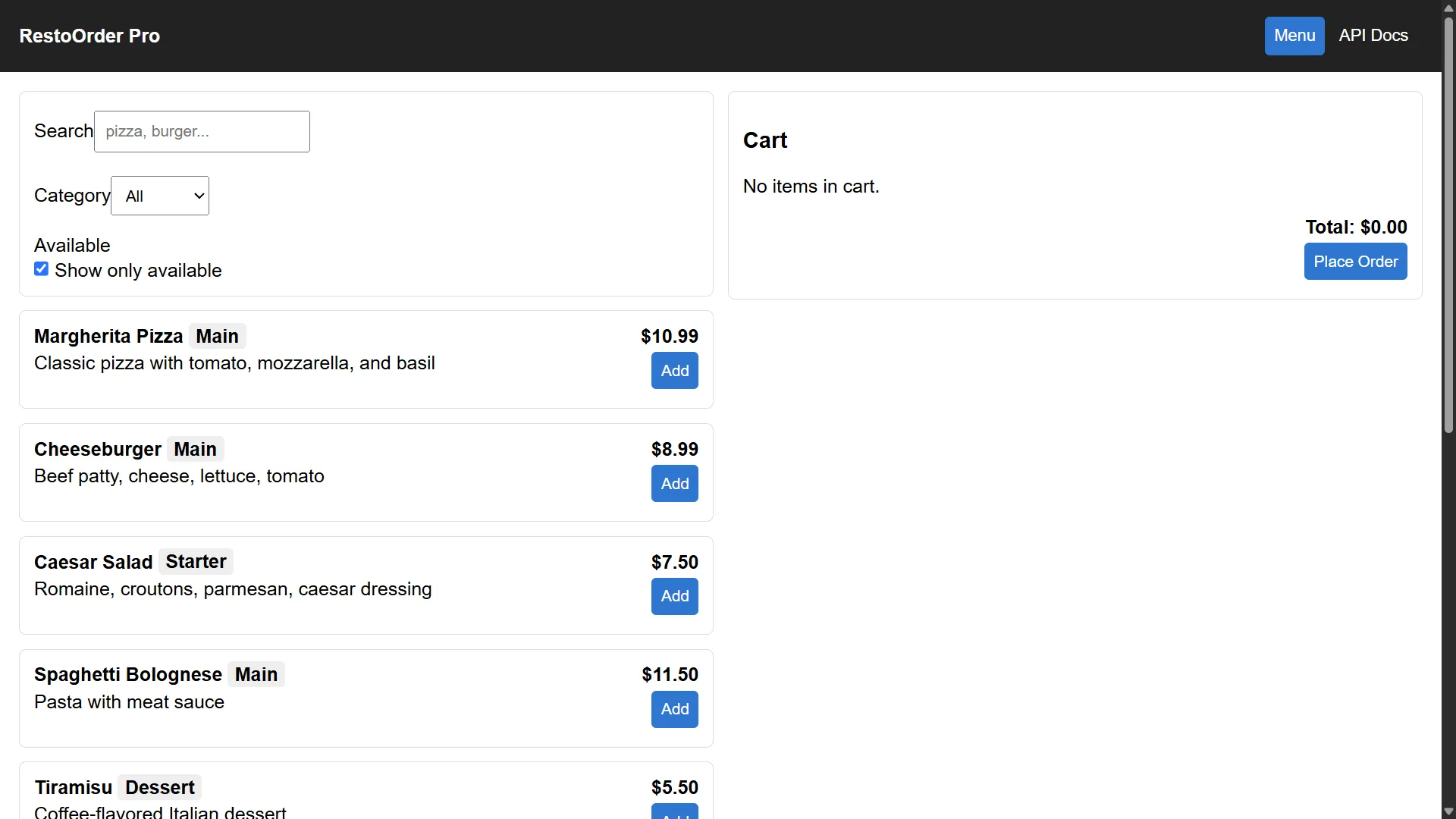
RestoOrder Pro: An online ordering app created using gpt-5-511
RestOrder Pro
A production-ready Restaurant Online Ordering web application built with Express (Node.js), React, PostgreSQL, and Nginx. Theme: Restaurant online ordering. Framework: Express. Technologies: Node.js, Express, PostgreSQL, JWT Auth with RBAC, React (Vite), Swagger/OpenAPI, Docker, Docker Compose, Nginx.
Download the generated apps for your own research and testing
I wanted to make the generated web applications available for other researchers to look at them and use them for their own experiments. With such a large set, I’m sure I’ve missed some security issues that others can find.
You can download the web applications generated for this analysis from Hugging Face using this link: harisec/vibe-coded-web-apps.
Scanning all the apps with static analysis tools
Next, I scanned all the generated web applications using multiple static analysis (SAST) tools and compiled a list of the most common vulnerabilities found in the apps.
Here are the most common vulnerabilities reported by SAST tools:
However, this is not the true picture, as most of these aren’t real. I manually analyzed a few dozen of the most serious issues reported by SAST tools and I was only able to find a handful that were not false positives.
Overall security level of vibe-coded apps
Compared to some of the insecure early AI code assistants, the code generated by modern LLMs is now much better from a security point of view, especially with the bigger models. I saw far fewer cases of SQL injection, XSS, path traversal, and other common vulnerabilities than I expected.
Here is a code fragment from RestoOrder Pro that prepares and executes an SQL query, which is the first place to check for SQL injection vulnerabilities:
As you can see, the code properly validates the input and uses parameterized queries to prevent SQL injection. It’s also protected by requireRole('admin'), strictly validates inputs by whitelisting status values and parsing the id as an integer, and uses parameterized SQL (the $1 and $2 parameters). Apart from avoiding SQL injection risks, it also prevents mass assignment by accepting only the status.
Finding typical vibe-coding issues through manual analysis
After running the automated scans, I manually reviewed a representative subset to confirm true positives. Then I did a full manual analysis of a small subset of the generated web applications (a few dozen) and was able to find some recurring security issues that seem to be typical of vibe-coded apps. They are mostly related to the use of hardcoded secrets, common credentials, and predictable endpoints.
Reuse of hardcoded common secrets
While analyzing the generated web applications, I found that many of them use hardcoded secrets for JWT signatures, API keys, database passwords, and other sensitive information. Interestingly, each LLM model seems to have its own set of common secrets that it reuses repeatedly across different generated apps.
The reason this happens is that LLMs are trained on code that contains many examples of hardcoded secrets. When generating new code, the LLMs tend to reuse these secrets from their training data instead of generating new ones.
Here are some examples of hardcoded secrets found in the generated web applications. You can find them in configuration files like .env, config.js, docker-compose.yml, settings.py, and others.
Example from docker-compose.yml:
Example from config.js:
Example from .env:
Example from settings.py:
Funnily enough, supersecretkey is used by multiple LLMs across multiple generated apps. I found that of the 20k apps analyzed, 1182 used supersecretkey somewhere.
Here are the most common secrets found in the generated web applications:
The most common secrets for each of the top 3 LLM models are:
Why predictable secrets can lead to vulnerabilities
Using hardcoded secrets can lead to serious security vulnerabilities, such as unauthorized access, account takeover, data leakage, and others.
As an example, in the RestoOrder Pro app generated by gpt-5, I found a typical JWT secret value in the docker-compose.yml file:
As you can see, JWT_SECRET is set to supersecretjwt, which is the most common secret used by GPT-5. Obviously, such a predictable value can be easily guessed by an attacker who has a list of common secrets generated by LLMs.
While it might seem a trivial issue, hardcoding a predictable secret value like this one may allow an attacker to forge JWT tokens and gain unauthorized access to the application. They might even create a JWT token with admin privileges and use it to access protected endpoints. Let’s see how this would work in practice.
Attack example: Forging a JWT token using a predictable secret
For an app that uses JWT tokens, when you log in as a normal (non-admin) user, you will get an HTTP response like the following that includes a token:
The JWT token is encoded but can be decoded using any JWT decoder tool, such as this online decoder. The decoded token payload looks like this:
To forge a JWT token with admin privileges, we can change the role field from customer to admin. The modified payload will look like this:
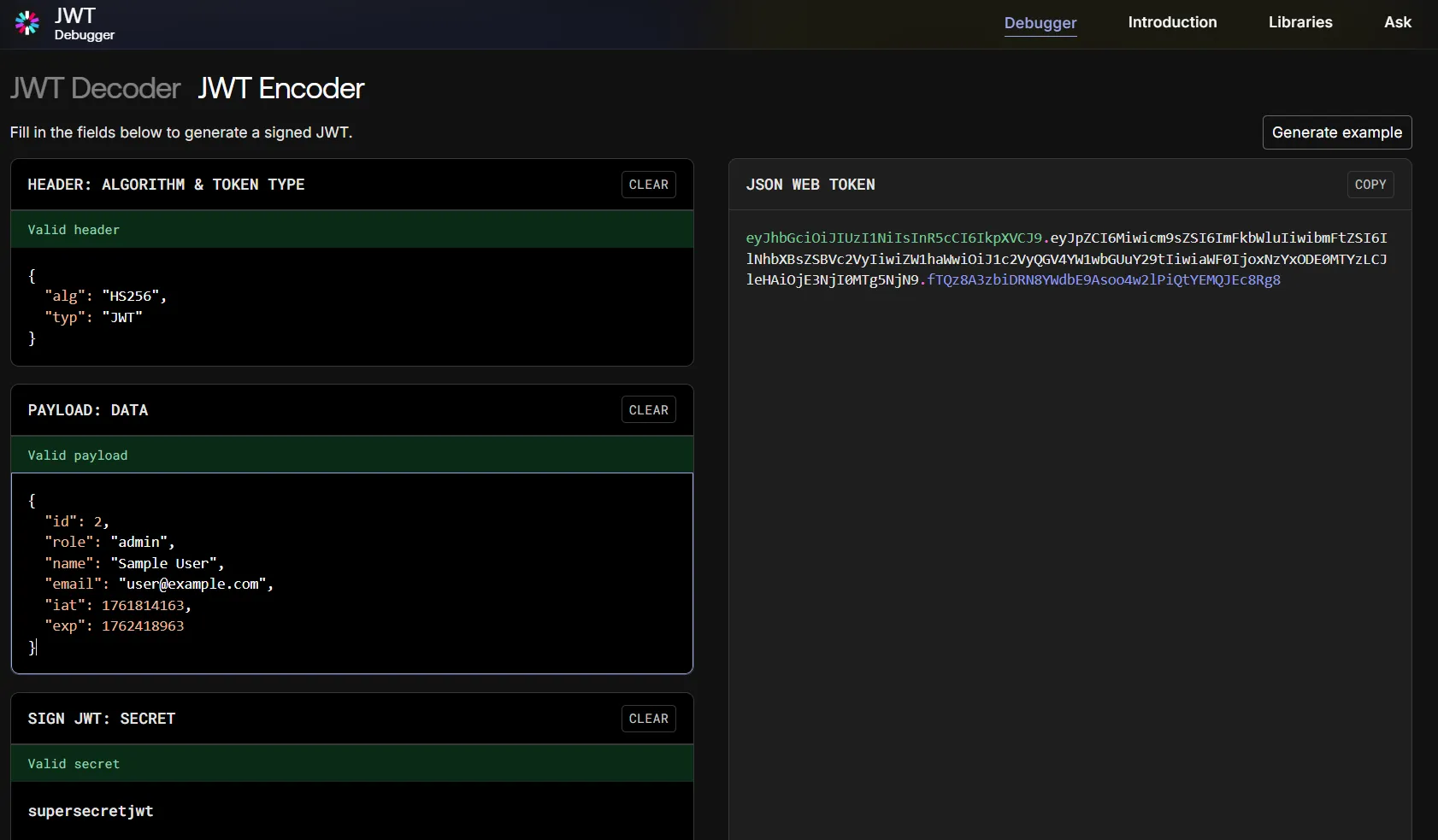
However, to encode and sign the payload that will give us admin access, we need to know the secret key used to sign it. In this case, this is easy – we know that the secret key is simply supersecretjwt.
Using the secret key, we can sign the modified payload and generate a new JWT token using the same online tool as before but in encoder mode. The new signed token will look like this:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6Miwicm9sZSI6ImFkbWluIiwibmFtZSI6IlNhbXBsZSBVc2VyIiwiZW1haWwiOiJ1c2VyQGV4YW1wbGUuY29tIiwiaWF0IjoxNzYxODE0MTYzLCJleHAiOjE3NjI0MTg5NjN9.fTQz8A3zbiDRN8YWdbE9Asoo4w2lPiQtYEMQJEc8Rg8
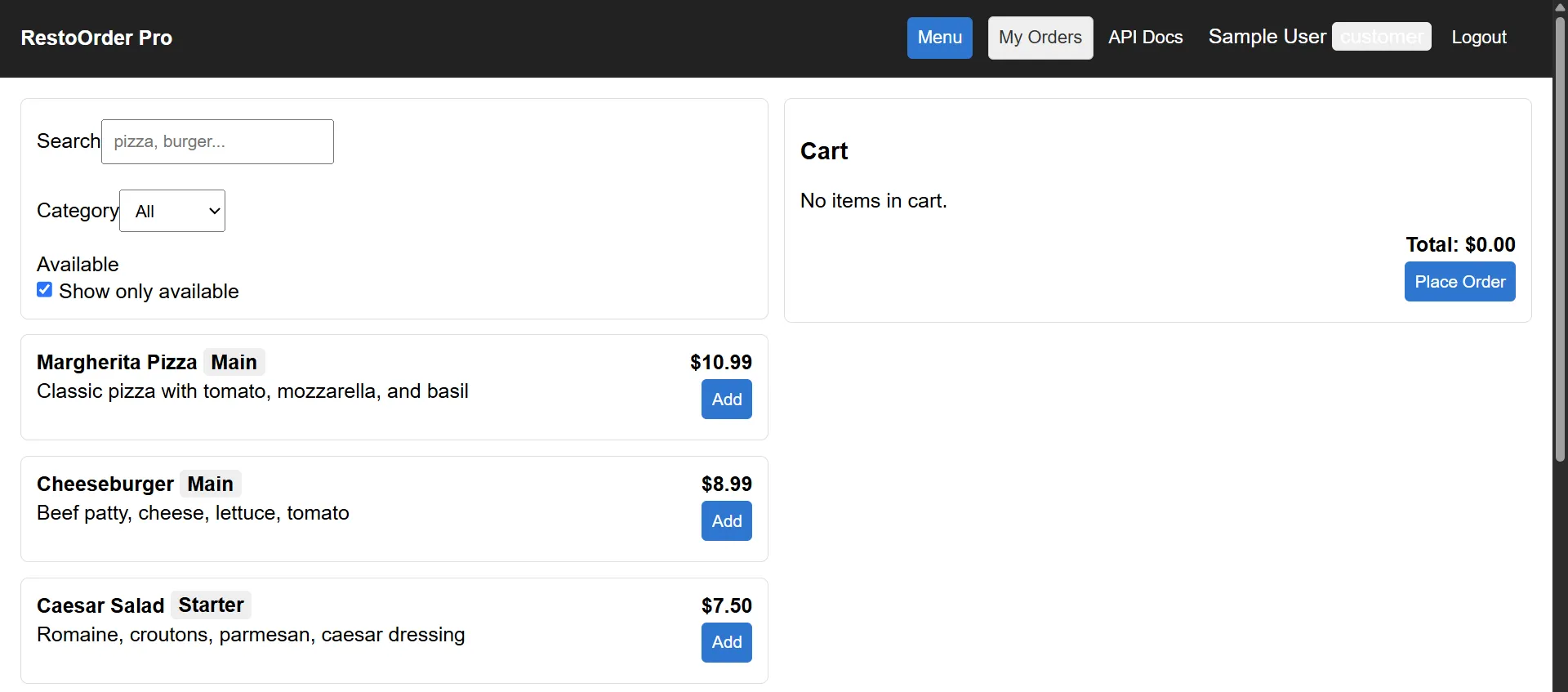
Without the forged token, we had access only to customer endpoints. This is how the application looks for a customer:
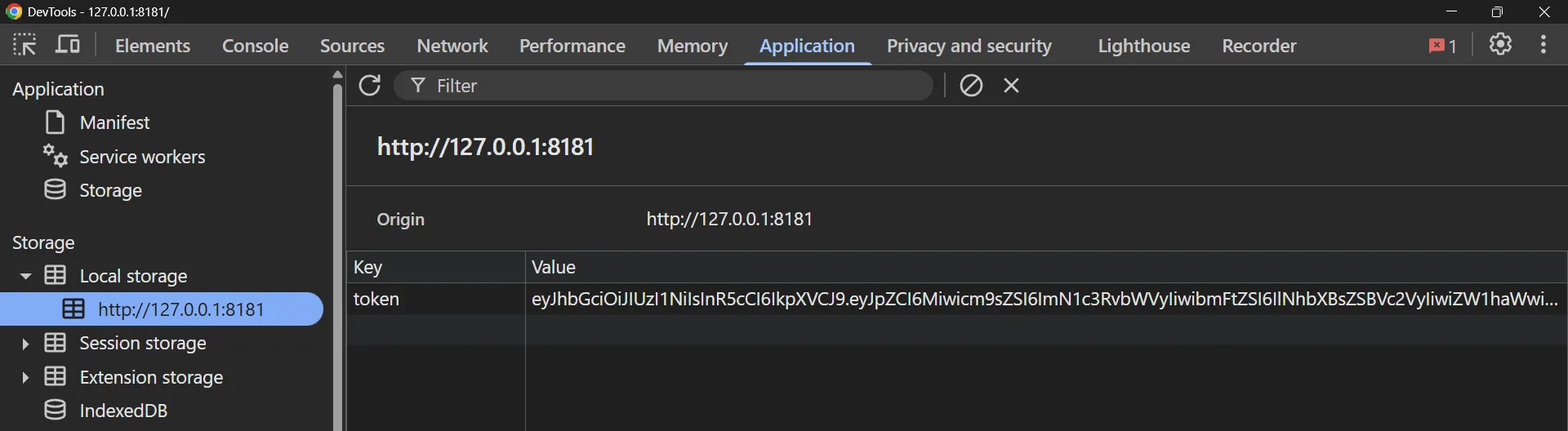
Looking around the application, we can see that the JWT token in saved in the browser’s local storage:
This means we can simply replace the token in local storage with the forged token we created earlier, and we should gain admin access to the application:
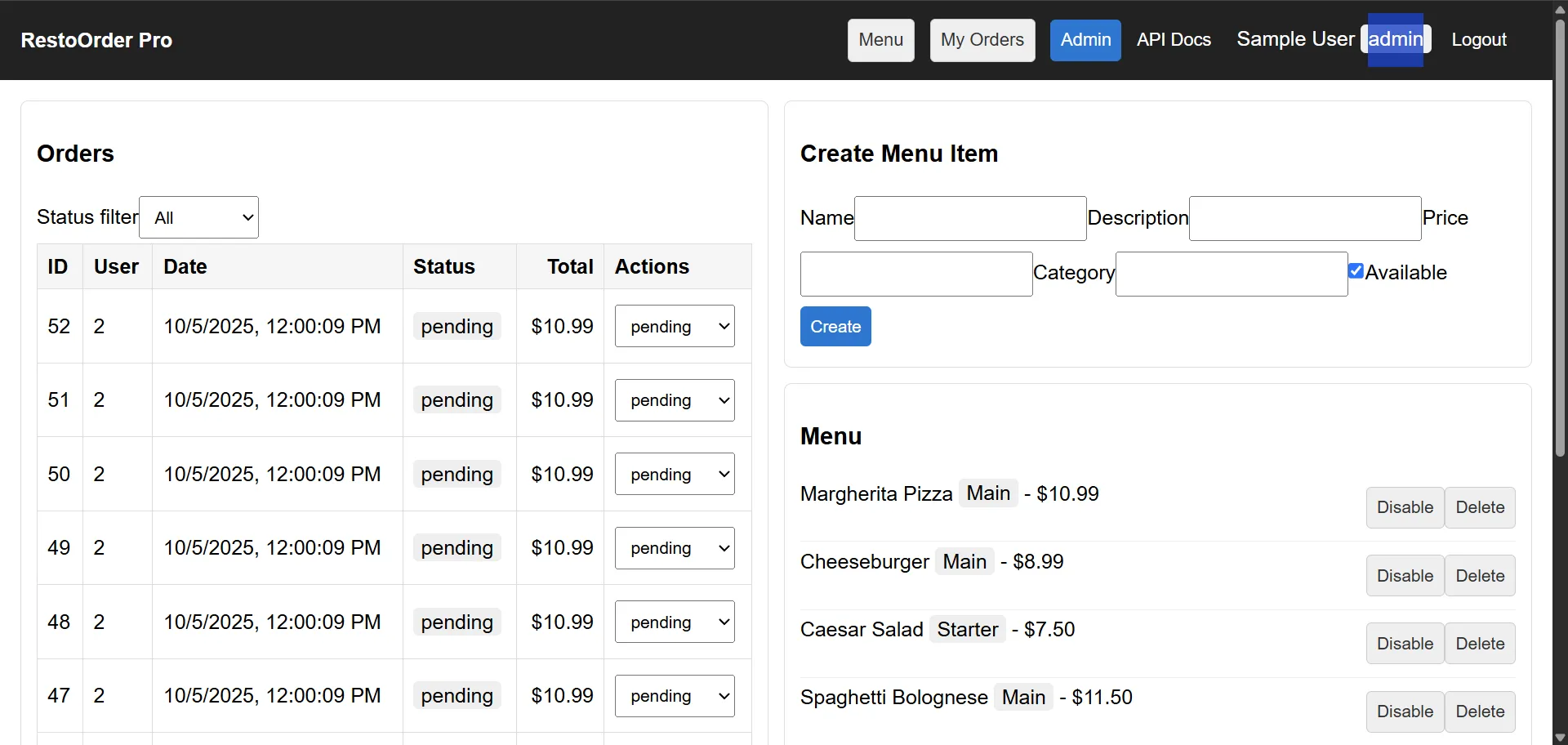
Sure enough, we now have access to the admin dashboard and can manage orders and menu items. As you can imagine, having this kind of weakness in a business application could have very serious consequences if a malicious attacker gains access.
Reuse of common credentials
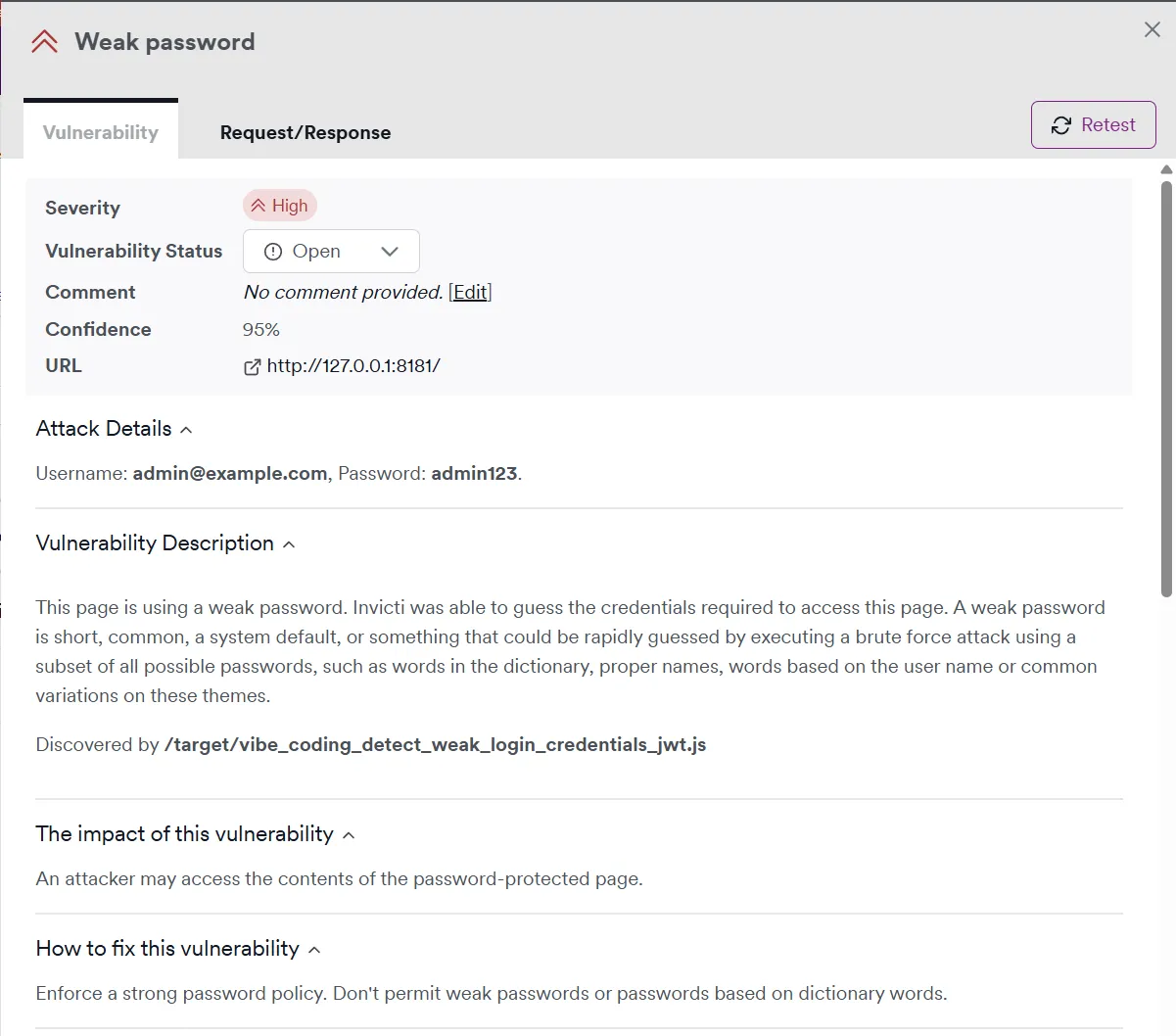
The vibe-coded web applications often use hardcoded common credentials for login and registration, such as user@example.com:password123, admin@example.com:password, user@example.com:password and others. Similar to the common secrets problem, each LLM model seems to have its own set of common credentials that it uses repeatedly across different generated apps.
The use of common credentials is possibly even worse than hardcoded secrets, as it can directly lead to account takeover, unauthorized access, and other security issues.
Here’s a list of the most common credentials found in generated web applications:
Reuse of common endpoints
When a new application is generated, it often includes common login and registration endpoints, such as /api/login, /api/register, /auth/login, /auth/register, /login, /register, and others.
While not necessarily always vulnerable, such predictable endpoints make easy targets for attackers, who could abuse them to register new accounts, log in with common credentials, and explore or exploit other vulnerabilities in the application.
Here are the most common endpoints found in the generated web applications:
New security checks in Invicti DAST for common vibe-coding vulnerabilities
As a result of this and other research, we’ve created and expanded several Invicti DAST security checks to specifically identify many vulnerabilities commonly seen in vibe-coded web applications:
- Invicti DAST now scans for common secrets, common credentials, and common endpoints in vibe-coded web applications.
- Each time the scanner finds a JWT token, we test if the secret used to sign the token is on our list of common secrets (which also includes all the typical vibe-coding secrets).
- We also test all the common login and register endpoints with all the common credentials found in vibe-coded web applications.
- The security checks include complex flows like trying to register a new account, log in to that new account, and test if the generated login token (JWT or otherwise) is predictable.
Here are two examples of security alerts that Invicti can raise for these vulnerabilities:

Conclusion: Security is improving, but LLMs bring their own flaws
Three years ago, our team analyzed the security of code generated by GitHub Copilot, which was the first widely used AI coding assistant. That analysis by Kadir Arslan concluded: “The results of my research confirm earlier findings that the suggestions often don’t consider security at all.” And this was only a coding assistant – back then, nobody would seriously suggest building a whole app using just AI.
Today, vibe coding is all around us, and many different tools are available. In my analysis, I was surprised at how much better modern LLMs are getting at avoiding typical vulnerabilities such as SQL injection. The most frequent security flaws are now caused by hardcoded secrets and similar information being replicated from the LLM training data. It’s hard to prevent such behaviors because they are built into models, so it’s important to be aware of them when coding and testing so you can fix those common flaws as early as possible.
Frequently asked questions
Experience the future of AppSec

